As a software engineer, I read and write application code every day. Occasionally, I get to work a little on CI/CD pipeline - Fix build issues, deploy a new application, etc. However, I have little understanding of how the entire process is orchestrated and automated.
So, I began with the goal of learning how to automate the entire stack: from infrastructure provisioning, configuration, application deployment, and starting and stopping the stack itself.
After spending some time crawling through Reddit and Stack Overflow, I gained a basic understanding of the whole process and the tools that are commonly used.
Overview
The target application is a URL shortener that makes a long URL into a shorter one, like TinyURL.
Backend repository: https://github.com/hanchiang/url-shortener-backend
Infra repository: https://github.com/hanchiang/url-shortener-infra
Technologies used:
Provisioning: packer, terraform
Configuration: ansible
Deployment: docker, github actions
Cloud computing: AWS EC2
Provisioning, configuration, deployment
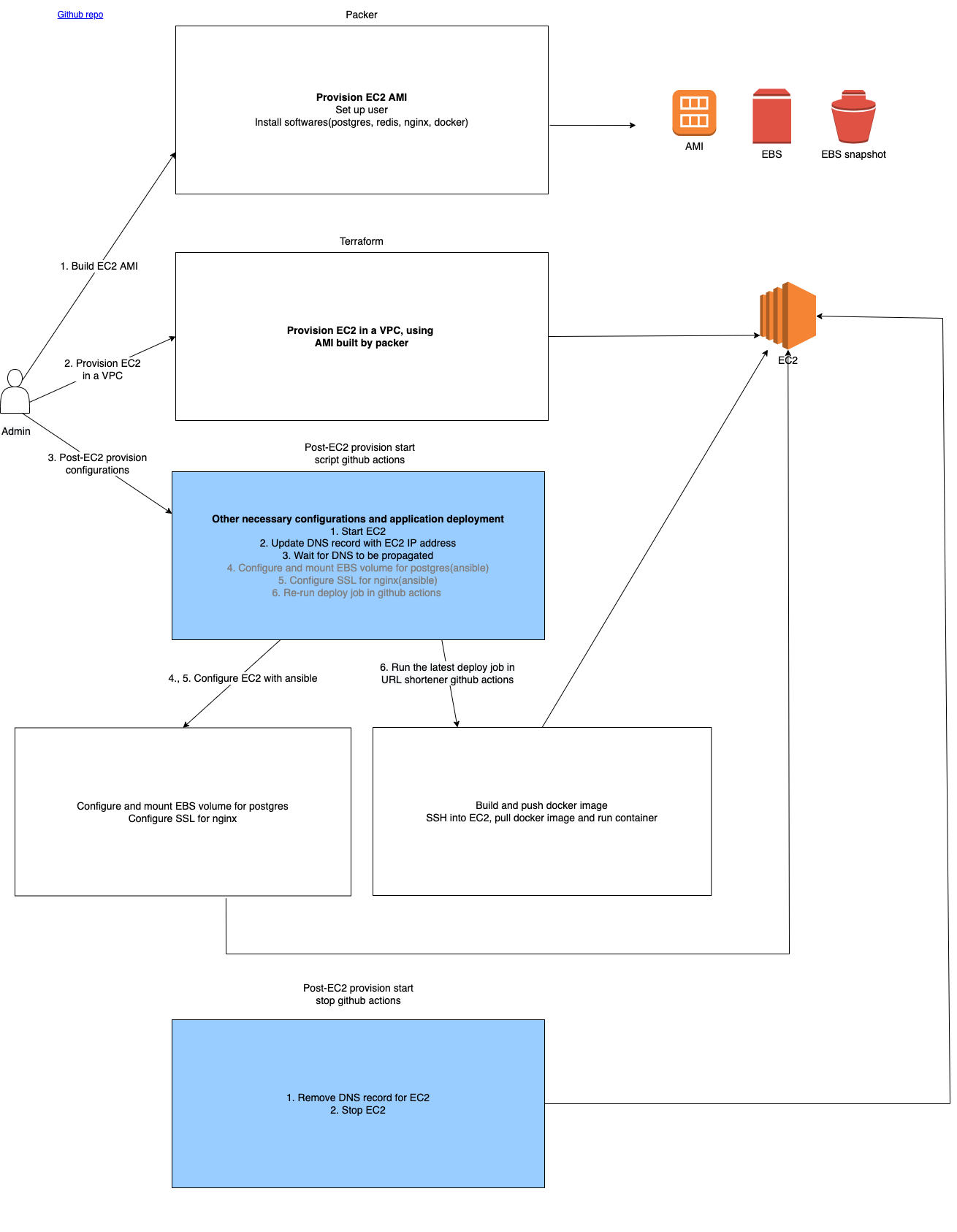
What is provisioning, configuration, and deployment?
It can be confusing to understand what provisioning, configuration, and deployment mean exactly.
My understanding is summarised in a timeline: provisioning -> configuration -> deployment
Provisioning
Provisioning is the process of setting up servers to be ready for use. In the context of cloud computing, this server is likely a virtual machine, on which a machine image is installed. Here, the operating system, along with other required software is installed.
In AWS terms, this means creating a VPC, subnet, route table, and EC2.
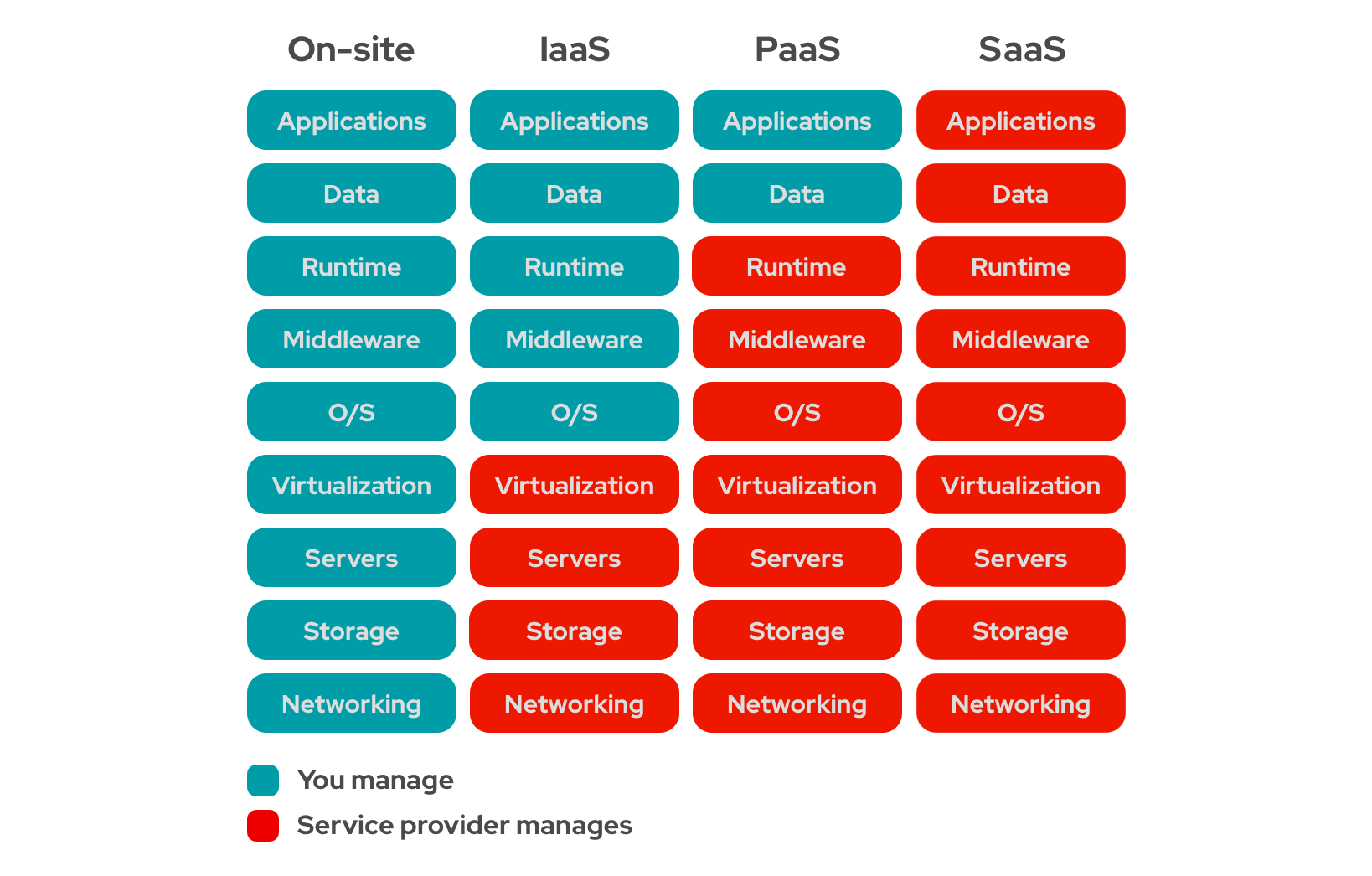
Source: redhat
The diagram above is useful to remember which layers we have to take care of under different cloud computing models.
Configuration
Configuration can be considered as an extension to the process of provisioning the server. Once the server is created, and loaded with the required software, it needs to be configured so that it is usable.
e.g. Configure PostgreSQL data directory, logging and authentication settings
Deployment
With the infrastructure ready to serve live traffic, an application can finally be deployed from an artifact repository to the server.
This could be as simple as SSH into the server, pulling a docker image, and running a container, or deploying to a kubernetes cluster with helm.
Visualising the whole pipeline
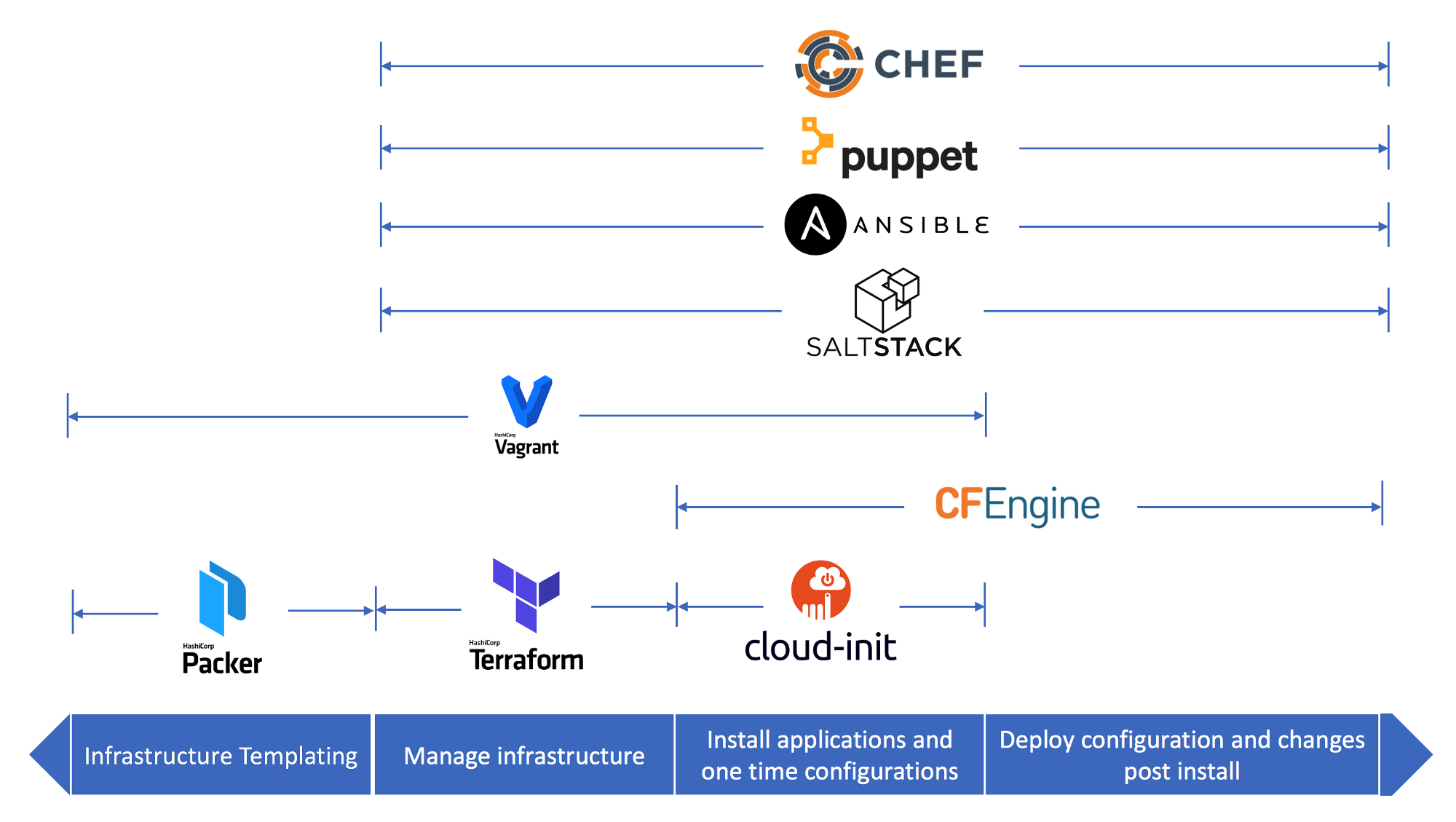
Source: golibrary
Deployment
I chose deployment as the first step because this is the easiest part of the pipeline. After building features and committing code, the next step is to deploy the new application.
Application setup
The URL shortener application is built on docker. Docker compose is used for the convenience of local setup. It consists of 3 containers: nodejs server, postgres, redis
Deploying the application
Application deployment is done with github actions.
The docker image is built and pushed to Github container registry. Then, it connects to the EC2 instance via SSH, pulls and runs the new image.
Provisioning
With the deployment part of the process handled, let's move on to provisioning the server.
There are 2 parts to provisioning:
Building image with packer
Packer is used to create a golden AMI with software and configurations, which is installed on the EC2 instance.
I used packer to create a user, install PostgreSQL, Redis, Nginx, Docker.
Using packer here takes advantage of immutable infrastructure, in which a standardised fleet of servers is built, achieving consistency and maintainability.
After that, the infrastructure is orchestrated with Terraform. It takes care of creating a VPC, subnet, EC2, route table, security groups.
Terraform is a tool that allows us to build the entire infrastructure in the correct order, and keeps track of the desired state, in a declarative style.
It can also detect state drift by synchronising its state to match the real-world state.
Again, the benefits of consistency and maintainability are present.
Configurations
Lastly, configurations is the missing middle piece in the entire pipeline.
After the system image is built with packer, and AWS infrastructure created with terraform, there are a few configuration tasks that need to be done in order for the server to be ready to serve live traffic.
This is done with Ansible, which is a simple yet powerful tool that allows us to configure servers in yaml.
I am using ansible to run shell scripts imperatively instead of managing configurations declaratively using the pre-defined modules, because I found it the easiest way to learn
Set up file system for postgres
Set up file system on a separate EBS volume to store postgres data, and other relevant data.
The reason for using separate storage from the root volume is so that all my application data is preserved each time a new server is provisioned.
Configure postgres
Configure postgres data directory and copy data over.
Configure SSL on nginx, redirect HTTP to HTTPS, and proxy all requests to the port that the URL shortener container is listening on.
Schedule start and stop
As an additional step, I wanted to schedule the start and stop of the EC2 and application via scheduled workflow in github actions.
This consist of the tasks defined in the configuration step, as well as interaction with AWS CLI and Github API.
The script can be found here
Summary
The end result is a complete pipeline from infrastructure provisioning to application deployment. Now that I have a basic understanding of DevOps, my next step is to explore observability.
Check out the project
Website: URL shortener
Backend repository: https://github.com/hanchiang/url-shortener-backend
Infra repository: https://github.com/hanchiang/url-shortener-infra