First software engineering role: A year in review

Software engineer based in Singapore
Welcome to my website, where I write mostly on tech-related content to share the things I learned from people and from building projects using different tools.
My interests are in tech, traditional finance, cryptocurrency.
It has been 1 year and 2 months since I started working full time in 2019 Feb 25. Much has happened at work, especially at a small company like mine where situations and decisions can change rapidly.
I thought this would be a good time to take a step back and recount the ups and downs in my first job so far.
Good news
Let's start the post on a positive note!
Great Mentorship
When the student is ready the teacher appears
I can confidently say that mentorship is the greatest gift that I have received in my team. I joined as the first engineer, fourth employee of the company, and started the entire technical system on a blank slate.
The beginning
During the initial phase of my onboarding, I worked closely with my manager, CTO of the company, on various application exercises and discussions and readings on software engineering principles such as Domain Driven Design, consistency in distributed systems, data flow in redux, among others.
After going through the exercises, I worked on the initial mobile application prototype demonstrating authentication, identity, and search workflow, together with the corresponding backend services. The regular technical discussions as I learned about data modelling, APIs design on the backend, and component organisation, data logic layer in the frontend.
The growth
As the rest of the engineering team got formed, my manager told me that I was assigned frontend responsibilities, and asked for my preference in areas of responsibility.
I told him that after I enjoyed the work on backend over the past few months and would like to do more backend work moving forward. Shortly after, my request was approved and I continued working on the backend services, while learning from a senior backend engineer, who has 10 years of experience building large-scale systems and leading a team of engineers.
Just to name some of the learnings that I took away from the senior backend engineer:
- Designing API with backward compatibility
- System-wide design considerations such as API versioning
- Design of stateful and stateless logic in API services
- Importance of idempotent operations in distributed systems, where failures and retries are expected
- Importance of identifying race conditions in concurrent operations that manipulate the same data set
- Writing and maintaining a reusable library with common functions
- Good software engineer practices such as DRY, SOLID, TDD.
My growth continued as we expanded the scope of work to application and database performance testing, design of cron jobs, task queue, search optimisation with redis sorted set.
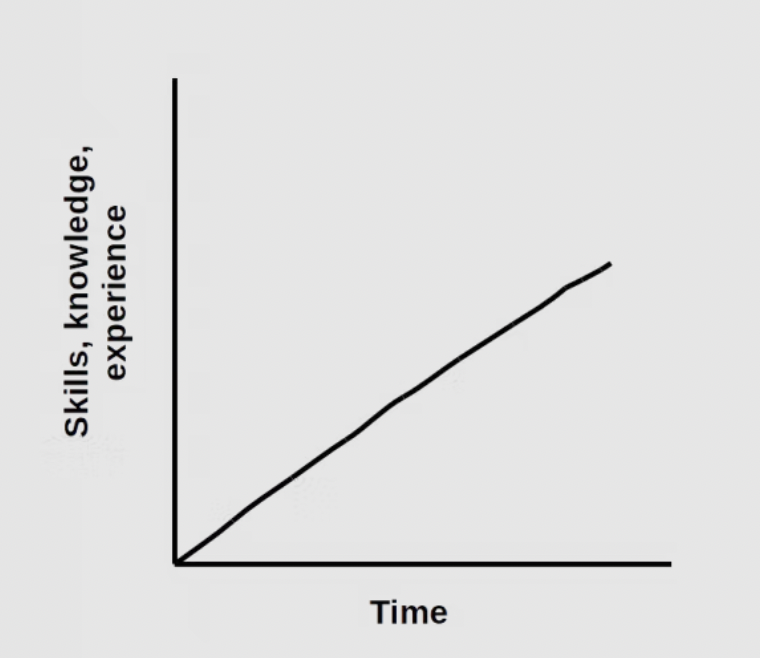
One important point to note is that growth is not linear, or put in another way, growth does not take place in equal proportions to time.
What I thought growth looks like
What it actually looks like
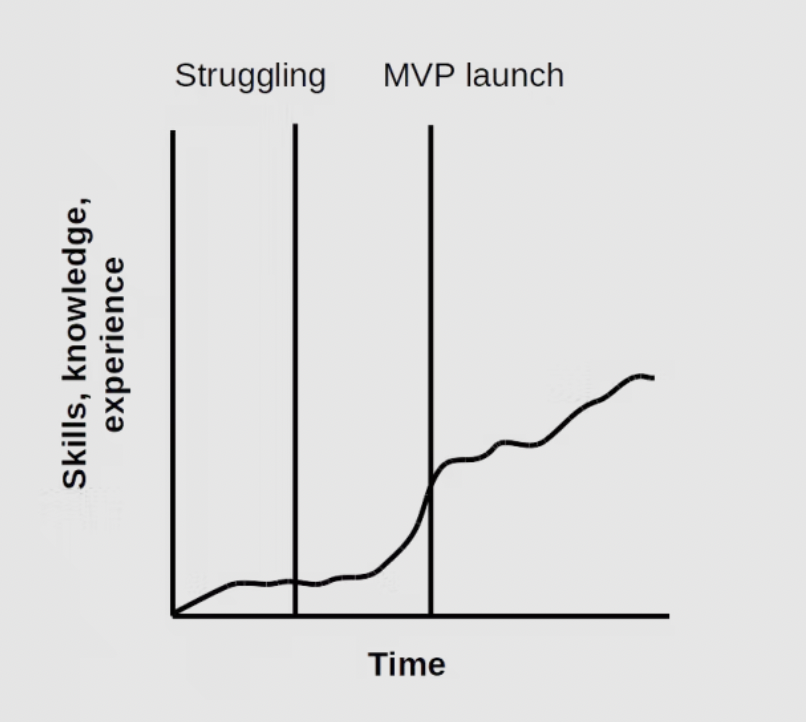
Looking back, I am happy and grateful to have the opportunity to learn from a great manager and senior engineer.
Initiated a team discussion
Conflicts are inevitable. Avoid them and they will eventually you find anyway
Soft skills is one of the most important skills in life, and transcends any kind of professional work, so it makes sense for everyone to have a certain level of proficiency at it.
I would say that as a person and a software engineer, soft skills has not been one of my strengths all this while, and that is why it is one of my priorities for my professional life.
Among incidents which involve conflict resolution, intra and inter team clarifications, one of them stood out.
There was a disagreement between the senior engineer and I regarding the approach for API versioning. My approach was to add endpoint-specific API version URL path, i.e. /v2/some-api, the senior engineer's approach was to add system-wide API version in request header, i.e. api-version: <api-version-here>.
Both of us debated about the benefits and drawbacks of the both approaches over slack and in person, and are unable to accept that the other person's approach is much more superior in terms of scalability and maintainability. Even with the CTO roped into the discussion, it resulted in a stalemate because none of us have worked with both approaches before to be able to give an unbiased assessment.
After a few days of back and forth discussion that led to no outcome, I decided to get the rest of the engineering team's input and called for a meeting. Both the senior engineer and I presented our cases and argued for the benefits and drawbacks, which I will summarise below:
API versioning via URL approach
Benefits
- Failures are detected earlier in the request response cycle at API gateway
- Able to track the version of each API endpoint independently
Drawbacks
- Duplicate entries in API gateway
- Quick and dirty implementation, may not scale well
- May result in application logic duplication if it is not well thought out
API versioning via header approach
Benefits
- Adhere more closely to HTTP design guidelines
- No duplicated entries in API gateway, code duplication in backend services
- Clients can use a single global API version, reducing overhead to keep track of versioning for specific endpoints
Drawbacks
- Failure detection is shifted upstream to backend services. An improper logic in handling missing/invalid API version break all requests coming from clients
- Require additional effort to make sure that the correct logic is used for different endpoints with different breaking versions, to prevent wrong code paths from being triggered, causing undesirable behaviours
Debate outcome
After every other member, besides the senior engineer and I, had shared about their experience and opinion, they took a vote which results in an even split between both approaches. At this stage, it was clear that the merits and drawbacks for both approaches are rather balanced and the team does not have a strong preference towards one.
Before deciding on an approach, we listed down the criteria for a good design and agreed that no APIs are always stable, therefore proper documentation and deprecation of APIs need to be accounted for.
Given the fact that we are under time constraint, none of the engineers belongs to "know-it-all" category of programmers, and we don't believe that there will be a whole lot of breaking APIs over the next couple of years, therefore we decided to go with the header approach.

Optimisations
Premature optimisation is the root of all evil. Intentional/ignorant non-optimisations is however a greater evil
As software engineers writing applications in high level programming languages, we get to enjoy the productivity that they bring and are able to push features out to production in a shorter time. However, there is a tendency to gloss over resource usage and performance implications, especially for junior engineers.
It is important to write software with resource planning and performance/cost optimisation at the back of the mind, rather than rushing the code out and leaving it up to the runtime to hopefully sort things out themselves, a.k.a throwing money at a problem.
The ability and foresight to architect a solution with specific performance requirements for certain business critical functions, anticipate possible issues, design a plan to tackle them, keeping in mind performance cost tradeoffs, will most likely save precious time and money further down the road.
Such things usually comes with experience. e.g. Use a JSON field to store user preference in MySQL instead of 10 diffferent columns, which could possibly increase in the future.
However, be careful not to fall into the trap of premature optimisation, especially if the performance/cost gains are not tracked, the benefits are not clear, or the solution itself does not solve the actual problem and may create further problems:
- Moving a few lines of code from a function into the main function to save the cost incurred on a function call.
- Using redis to speed up queries instead of using proper indexes in RDBMS

Bad news
After all the great things, let's talk about the other side because not everything is perfect.
Timezone unaware
UTC is not the cure-all to timezone difference
The first major mistake was the failure to take timezone into account when developing the application. What happened was that the user's time input was taken in their timezone, submitted to the server and converted to UTC, and finally converted to the merchant's timezone to search for availability.
What should happen, instead, is to search for the timeslot directly without timezone conversion. For example, If I am in Singapore and selects 8PM, the server should search for 8PM timeslots for all merchants, independent of end-user and merchants' timezone. The results should then be displayed in the merchants' timezone.
Accidental deletion of database
I dropped all the tables in the staging database and not realise it until 15 minutes later
One of the greatest sins in the world of software is to delete a production database. I have fared slightly better, because I accidentally wiped out a staging database while I was multitasking like the hero I thought I was.
What happened was I replaced a local database by dropping all tables and running the scripts to recreate them, which is fine. What went wrong I had 3 connection tabs opened in MySQL Workbench, 1 for local, staging and production.
I was rapidly switching between local and staging to check the database schema, and the next thing I did was to drop all the tables in the staging database and not realise it until 15 minutes later.
What followed was an immediate restore to the last database snapshot, and everything went back to normal. Things would have been so different if I had deleted a production database instead.
After this mistake, which could potentially be much worse, I learned to slow down and be more careful when dealing with databases.

JWT tokens expiry
Access token and refresh token were set to expire at the same time?!
According to standard software engineering practices, my team uses JWT to authenticate and authorise access to our API services.
Initially, the access token was set to 90 days expiry and refresh token was set to never expire.
The problem came sometime later when the refresh token was somehow set to also expire after 90 days. This problem took us some time to catch because of several lapses.
Gaps in mobile application
First, the mobile application did not have a fallback when the refresh token request fails, and it will fail silently, manifesting as no data showing up on the application no matter what you do. So any user interactions will not be meaningful after 90 days, even though the application is still working, unless the user logs out and log in again.
Gaps in alerts
Second, the alerts for JWT failure via AWS lambda authoriser were not configured properly. It was set to trigger when the number of failed requests surpasses a certain threshold. However, the traffic was not high enough to trigger this alert
After identifying the problem, and having a quick discussion, we applied a quick patch as a temporary fix, so that users can still continue to use the mobile application, and designed a long-term solution to fix this properly afterwards.
Improper monitoring configuration
No PagerDuty calls mean everything is perfect right?
This point is related to the previous point about lapses in alerts. My team uses Datadog extensively for its logs management, metrics tracking, and monitors and alerts.
We have set up a bunch of monitors to send us alerts via slack integration for API level failures. For service level failures which are more critical, PagerDuty integration is used to send alerts to our phone for emergency.
So around 2 months after launch, there were no PagerDuty alerts at all, despite multiple API failures, containers crashing occasionally. No one suspected anything because there were no obvious signs of improper PagerDuty configuration.
This problem was discovered when I caused an outage in search service because I was tweaking the domain path in AWS API gateway, and for some reason the domain path for search service changed to an invalid value and I saved the change without noticing it.
Luckily, the Datadog monitors picked that up and alerted us via slack, which resulted in a swift recovery. This lead us to the discovery that the PagerDuty integration was set up wrongly because it should have been triggered when a service is down.
The impact of this incident was that the search service was down for around 12 minutes.
By now, it is clear that not only are sufficient monitoring and alerts important, but they should also be tested to ensure that they work in the way that we expected them to, and not let false negatives slip through.
Gaps within the engineering team
Move fast, fail fast, except don't fail too much to the point you can't recover
The engineering team of 7 was built to allow individual members to run at top speed, which proved to work well as we released 3 products within 5 months of intensive work. However, upon deeper examination of the work processes, a few but significant gaps can be found.
First, the engineering team was split according to their roles: backend, web, mobile, infrastructure. While the engineers within their own role are proficient and built features at great speed, there was significant slowdowns for system-wide workflows that bridge multiple roles.
An example would be the user sign up journey that triggers an email notification asking users to click a branch.io link to verify their email, which brings them to the website to complete the verification, and displays a button with branch.io link to open up the mobile app.
In the above examples, there are 4 components of the system at work: mobile, backend, web, branch.io.
The team implemented this workflow as a series of independent work with the other component, e.g. mobile and backend, backend and web, web and mobile, which seemed fine, until we received a customer complaint from the product team that the verification link in the email doesn't work, and this was just 1 day after launch.
It was later determined that the branch.io setting for the website was not updated because it had to be done after the mobile application went live. Apparently, none of the team knew about this except the engineer working on the web.
A possible reason as to how to this could happen could be that was that the team did not have a thorough understanding in terms of the end to end user registration workflow.
Gaps between engineering and product team
Humans are by nature social animals
I feel that communication gaps between engineering and product team is one of the greatest challenges in my work so far, and is one of the areas that still needs more work on.
This is an issue that happens anywhere, that has also been debated about back and forth, with discussions in favour of engineers while bashing product managers and vice versa.
On the other hand, there are also well thought out discussion on how both teams can work well together, such as this by the engineering manager, asana, intercom.
These are what I found to be helpful in the product engineering collaboration:
For engineers
- Have an active voice, raise questions and clarifications as soon as possible rather than deferring them.
- Do your homework and read up on the product requirements beforehand. Err on the side of asking too many questions, because many engineers are rather reserved, and that includes me.
- Advise and update effort estimation on non-trivial work. The purpose is to communicate the effort required and implications for the system and roadmap
For product managers
- Be more involved in product planning by showcasing research, demonstrating motivation and value proposition of features, and how they fit into the whole UX.
- Have accurate and up-to-date information on product requirements

Closing
Finally, I want to close this off with a spirit of gratefulness, to give thanks to the people that have shaped my work environment and daily work.
There are many more great things to come, some of which include multi-region and multi-lingual website deployment, domain names and SEO implications, multi-region cloud infrastructure deployment.