Instagram scraper: Find viral posts on instagram

Software engineer based in Singapore
Welcome to my website, where I write mostly on tech-related content to share the things I learned from people and from building projects using different tools.
My interests are in tech, traditional finance, cryptocurrency.
In the beginning of 2019, I was experimenting with niche pages on Instagram, and wanted an on-demand tool to find viral instagram posts of users in my niche. So, I created a small project to scrape viral posts from any instagram user.
There are various open-source projects such as instagram-private-api with more features like upload photo/video, manage follower/following, discover trending tags, etc.
For experimenting or automating workflow that requires such features, it is best to use of one these larger projects.
My main goal is to learn the process of inspection of web data, coupled with google search of course, to create a simple read-only tool to download best performing posts on instagram.
What is a viral post
The word "viral" hints at what a viral post is. Viral posts are posts that have reached a much larger audience than regular posts. This is the dream of all content creators, marketers, or any creatives who want to grow their audience base.
The challenge is to sample a few viral posts and work backwards to determine what factors contributed to their virality.
While there are no sure ways to make a post go viral, there are guidelines on how to create a viral marketing post in general and on instagram.
Determine whether a post is viral
From the engagement perspective, a viral post is one that has significantly higher engagement rate than other posts.
The definition of "significantly higher", "engagement rate" and "other posts" are up to us to decide.
I chose 50% for "significantly higher", number of likes for "engagement rate", and 20 most recent posts for "other posts".
In short, if a post has 50% more likes than the average number of likes of the 20 most recent posts, it is a viral post.
Of course, this is a naive solution as contextual information such as world and local events are missing.
Workflow to find viral posts on instagram
- Retrieve user profile
- Extract the relevant information using data from the previous step
- Retrieve user's media(photo/video uploads)
- Calculate the engagement rate of the top 20 most recent posts using data from the previous step
- Filter for viral posts using data from step 3 and 4
- Save to file
In step 1 and 2, we determine what information we need and where to find them.
In step 3, we figure out how to retrieve user's media by inspecting the HTTP requests.
At this point, the bulk of the work on Instagram is done. What is left is to transform the user media data and save it to file.
Step 4, 5, and 6 will be skipped because they are trivial.
1. Retrieve user profile
The first step is to retrieve information on a user profile, like username, follower count, following count, etc.
Let's use @9gag as an example for this exercise.
Go to https://www.instagram.com/9gag/
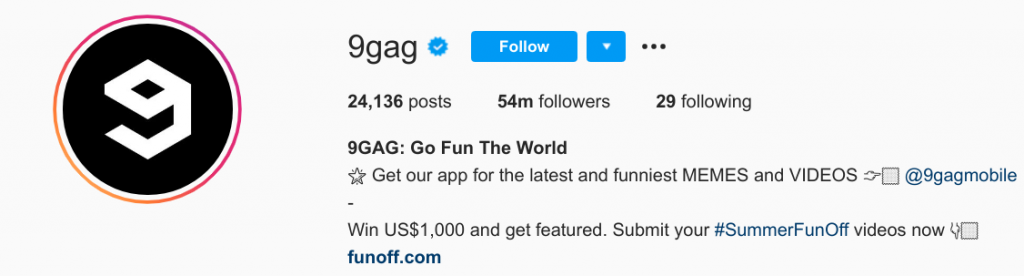
Fig 1. hmm much posts and followers
Right click on the page and go to "View page source", or hit CTRL + U. This brings us to the source code 9gag's profile.
To find out where to get the profile information, hit CTRL+F and search for "24136", which is the number of posts 9gag has.
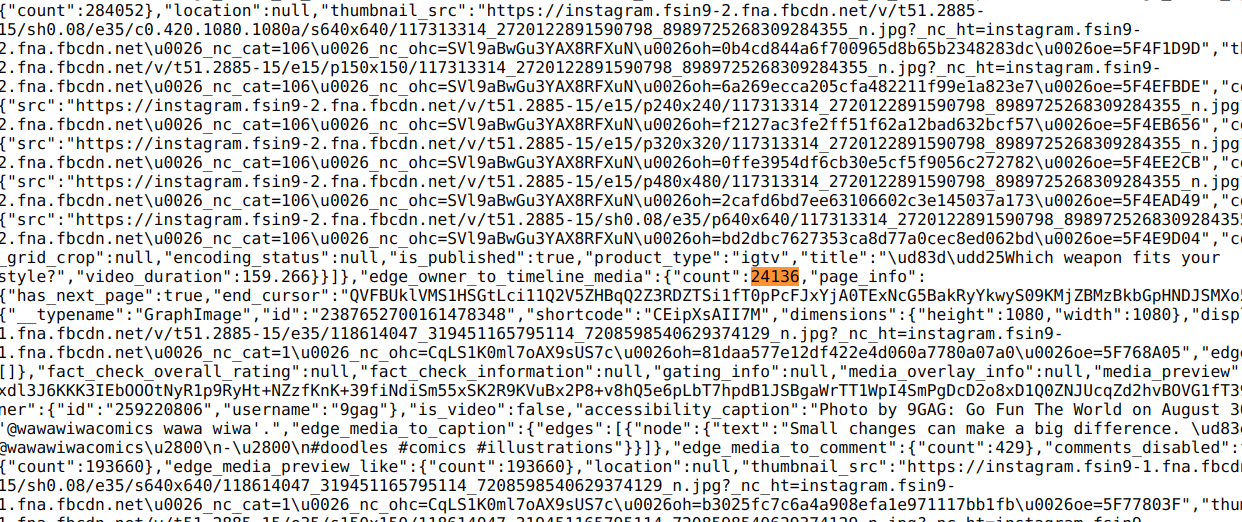
Fig 2. found the needle in the sea of gibberish
It looks like we can get some profile information from 9gag's source, but there is also a lot of unrelated data surrounding it.
After spending a few minutes inspecting the file, we can figure out that all information of a user is stored under window._sharedData.
Fig 3. start of the data block
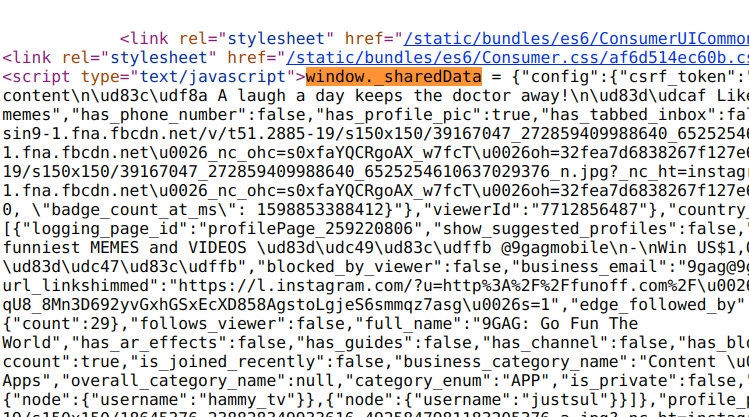
Fig 4. end of the data block

2. Extract the relevant information
Now that we have found out the place to look for user information, we need to extract them in order to do useful things.
The part of the data we are interested in is between the { after window._sharedData in Fig 3 and } at the end in Fig 4.
A pattern matching task means regular expression(regex) to the rescue!
Here is the magic pattern in javascript:
/window._sharedData = (.*);/
To try this out, copy the entire chunk of the window._sharedData, go to https://regex101.com/, paste it under "test string" and the regex above under "regular expression".
The whole javascript object is matched and we have 9gag's profile information on hand now.
Too much data!
But there is one problem, there is way too much data than we need. To visualise the data better, we can use a JSON prettifier.
Copy the entire javascript object, drop it in the json prettifier and click "make pretty".
Fig 5. finally found the data we are after
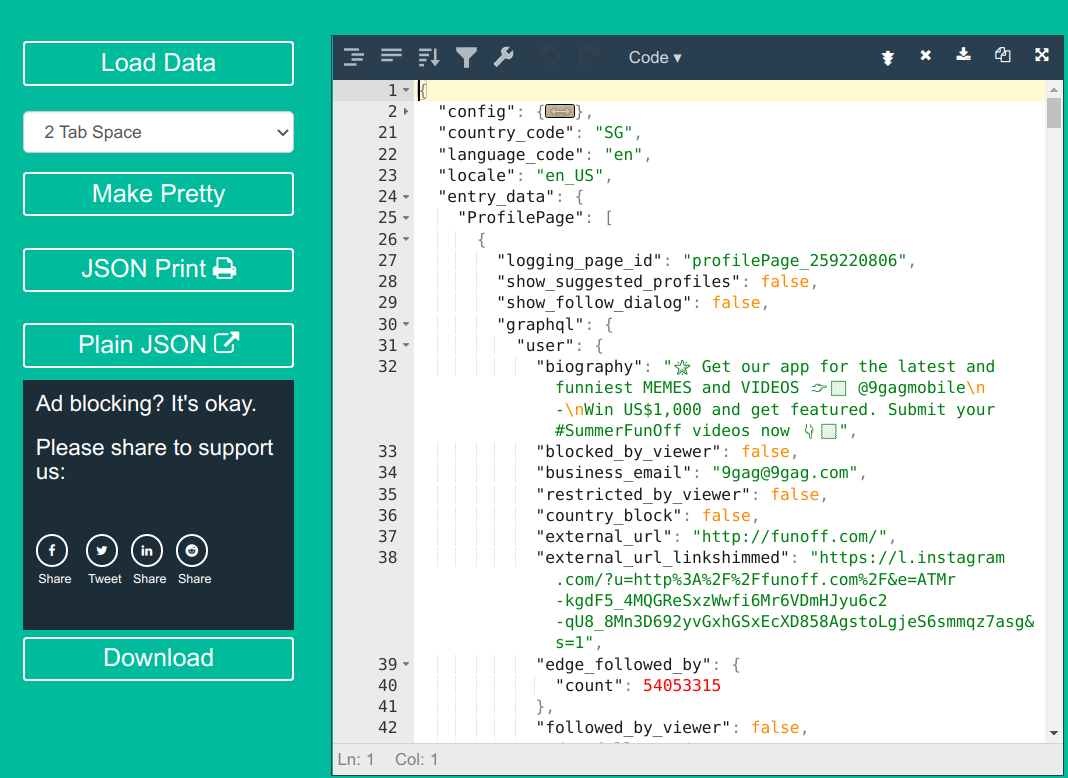
It became clear that the data we need is under entry_data.ProfilePage[0].graphql.user
3. Retrieve media uploads
This is the meat of the entire operation, and requires a little more inspection.
This time we will use the browser's network inspector and instagram's web API. Hit F12 or right click and go to "Inspect", select the "Network" tab, select "XHR" request type.
Still on 9gag's page, scroll down to trigger the spinning loader which will fetch more media. There will be an entry starting with ?query_hash=...... Double click on it and we will see the data for the first page of media.
Fig 6. the request to retrieve user media
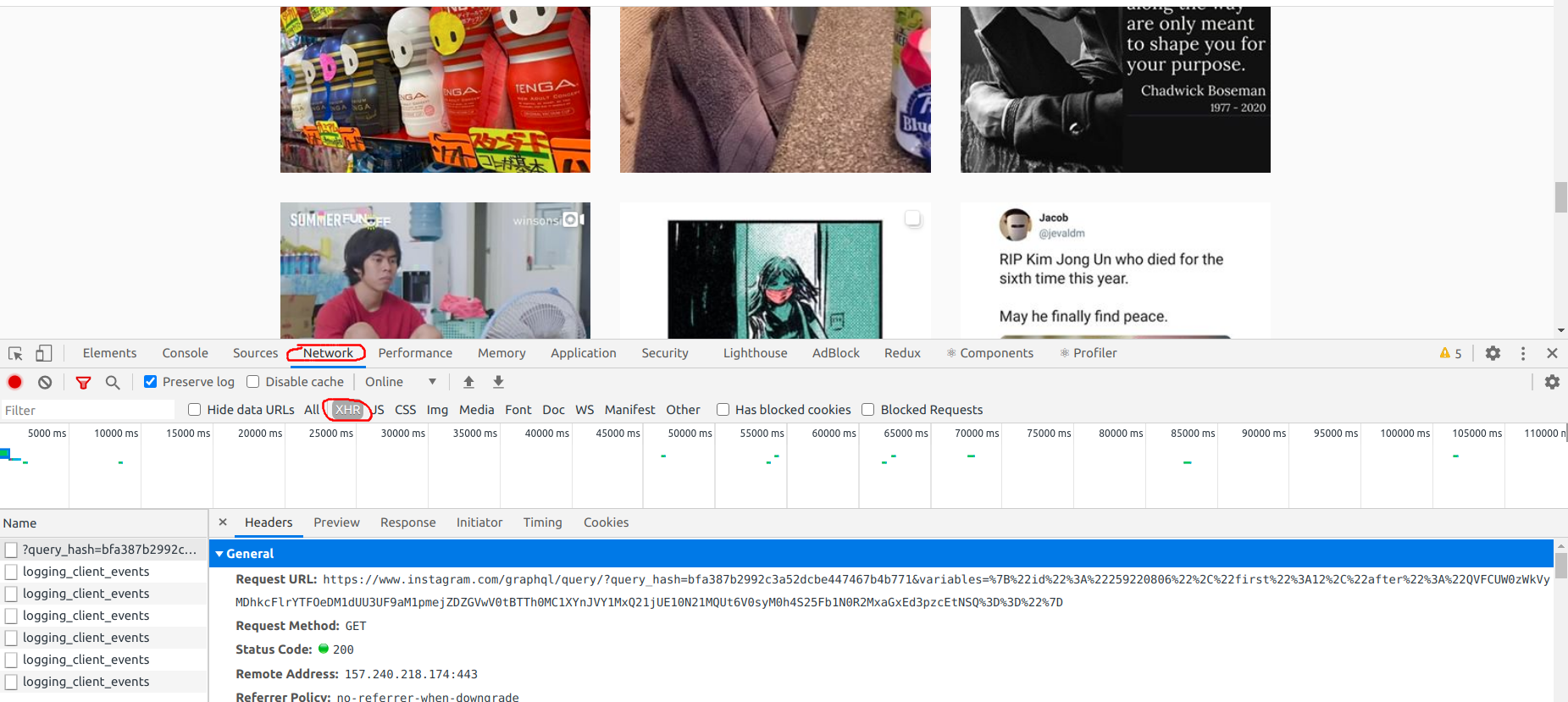
Fig 7. first page of 9gag's media
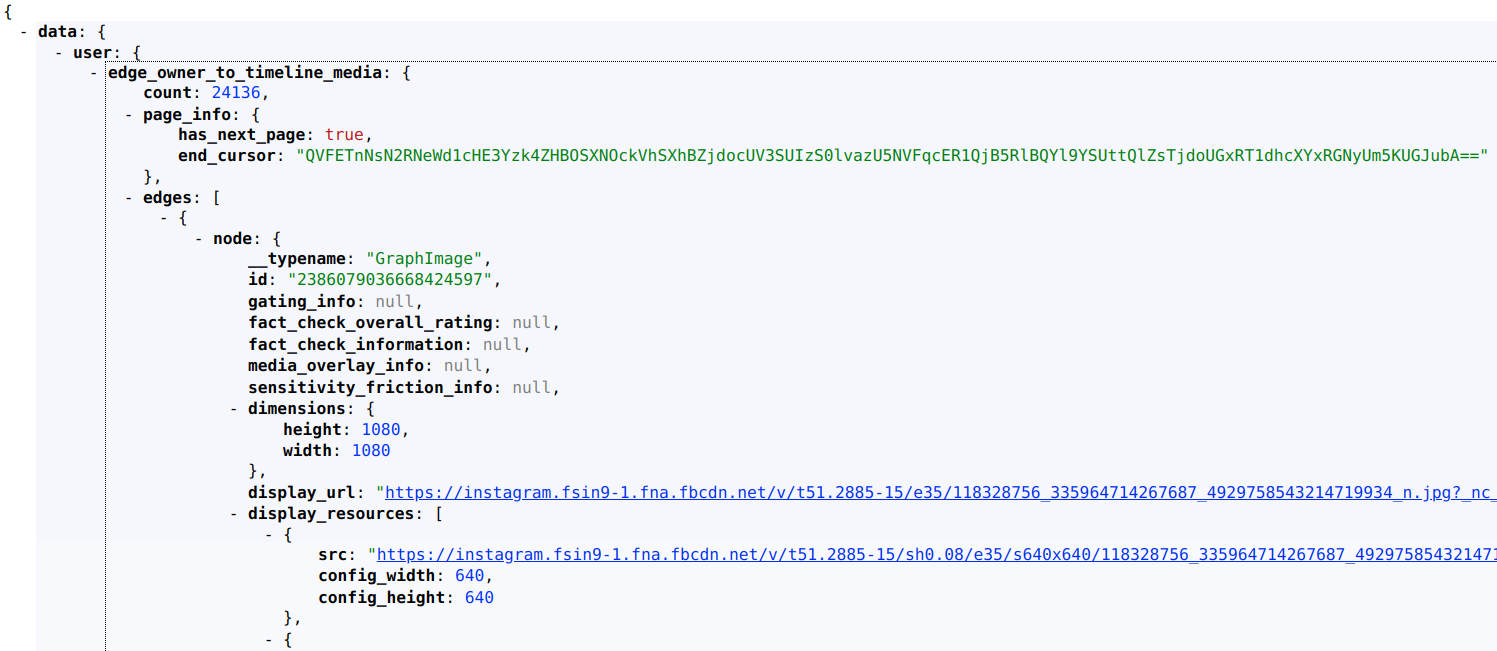
Deconstructing the media request
The full URL for the media request is https://www.instagram.com/graphql/query/?query_hash=bfa387b2992c3a52dcbe447467b4b771&variables=%7B%22id%22%3A%22259220806%22%2C%22first%22%3A12%2C%22after%22%3A%22QVFCUW0zWkVyMDhkcFlrYTFOeDM1dUU3UF9aM1pmejZDZGVwV0tBTTh0MC1XYnJVY1MxQ21jUE10N21MQUt6V0syM0h4S25Fb1N0R2MxaGxEd3pzcEtNSQ%3D%3D%22%7D.
The URL is unreadable because it is encoded. To decode it, paste it in https://www.urldecoder.org/ and hit "decode", or use the javascript's built-in decodeURIComponent function:
https://www.instagram.com/graphql/query/?query_hash=bfa387b2992c3a52dcbe447467b4b771&variables={"id":"259220806","first":12,"after":"QVFBRTg2Q2VlUjVFNnBQYzdCUjdSeXM3Z09rVjJCVW9QX1A4U2VQMU55a3dPdmZheEtOUTFrU2h4WTVUSlZRcW5ZV05GbW5BZEJ1YWhQZUZKNlFUd0lrcQ=="}
There are 2 important components: query_hash and variables.
query_hash determines the type of operation, which in this case is media retrieval.
variables is a javascript object which consists of the user id(id), number of media to retrieve(first) and previous page's end cursor(after).
This way of data retrieval is known as pagination, a way to fetch a large amount of data in small batches in order not to overwhelm the server.
Fig 8. simplified version of how pagination works

Gotta get 'em all
Now, we know how to construct the request to get media data, we just have to use has_next_page and end_cursor to retrieve the data until we are happy, or until instagram decides to activate the ban hammer. 🙊
Also, it looks like instagram imposes a limit of 50 items for each media page. So that's 483 requests to scrape all of 9gag's media.
If each request takes 1 second to complete, and we add a random delay of 0.5 - 1.5 seconds between each request, and ignoring everything else, it will take around 483 * (1 + 1) = 16 minutes to scrape all of 9gag's media.
Tips to scrape instagram safely
There is always a risk that instagram may issue an IP ban(temporary and permanent) when hitting its server programatically.
However, there are some guidelines to make this venture less risky.
1. Mimic human behaviour
This is the most important tip. No human will make requests in the same exact way every time, e.g. pausing for some time after every request, making 50 requests per second.
Add some random behaviour in the process. Pause for a random duration between 1-2 seconds after each request
Use common request headers to convince the server that the request comes from a real person using a web browser. Some of them are "user-agent", "accept", "accept-encoding", "referer".
This article provides some useful tips on how to avoid being blacklisted when scraping websites.
2. Instagram's rate limit
It was reported that the limit of media scraping is around 150-200 requests per 2 minutes. It is good to keep this in mind and experiment with it.
3. Instagram's soft IP ban
Instagram gets angry when we make a lot of requests in a short period of time, especially as an unauthenticated user.
When that happens, one of these two things need to happen:
- Wait it out
- Figure out a way to make request as an authenticated user(I have not figured it out yet. Help wanted?)
Conclusion
This was a little fun project to pique my own curiosity in finding viral posts on instagram. I hope this post is useful to inspire people to experiment with web development.
Feel free to check out my project!
Disclaimer
This post is intended to be educate and inform people of the possibility of retrieving instagram data from non-official ways, and is in no way endorsing such actions.
Do it at your own risk.