Project venturebites: A portal for asia tech startup events

Software engineer based in Singapore
Welcome to my website, where I write mostly on tech-related content to share the things I learned from people and from building projects using different tools.
My interests are in tech, traditional finance, cryptocurrency.
Earlier this year(2021), I worked on Venturebites with a friend, which is a portal for tech startup events in Asia.
I was actively working on it for 2 months to get the system up and running. As of today, it is not under active development.
Here are some screen captures:
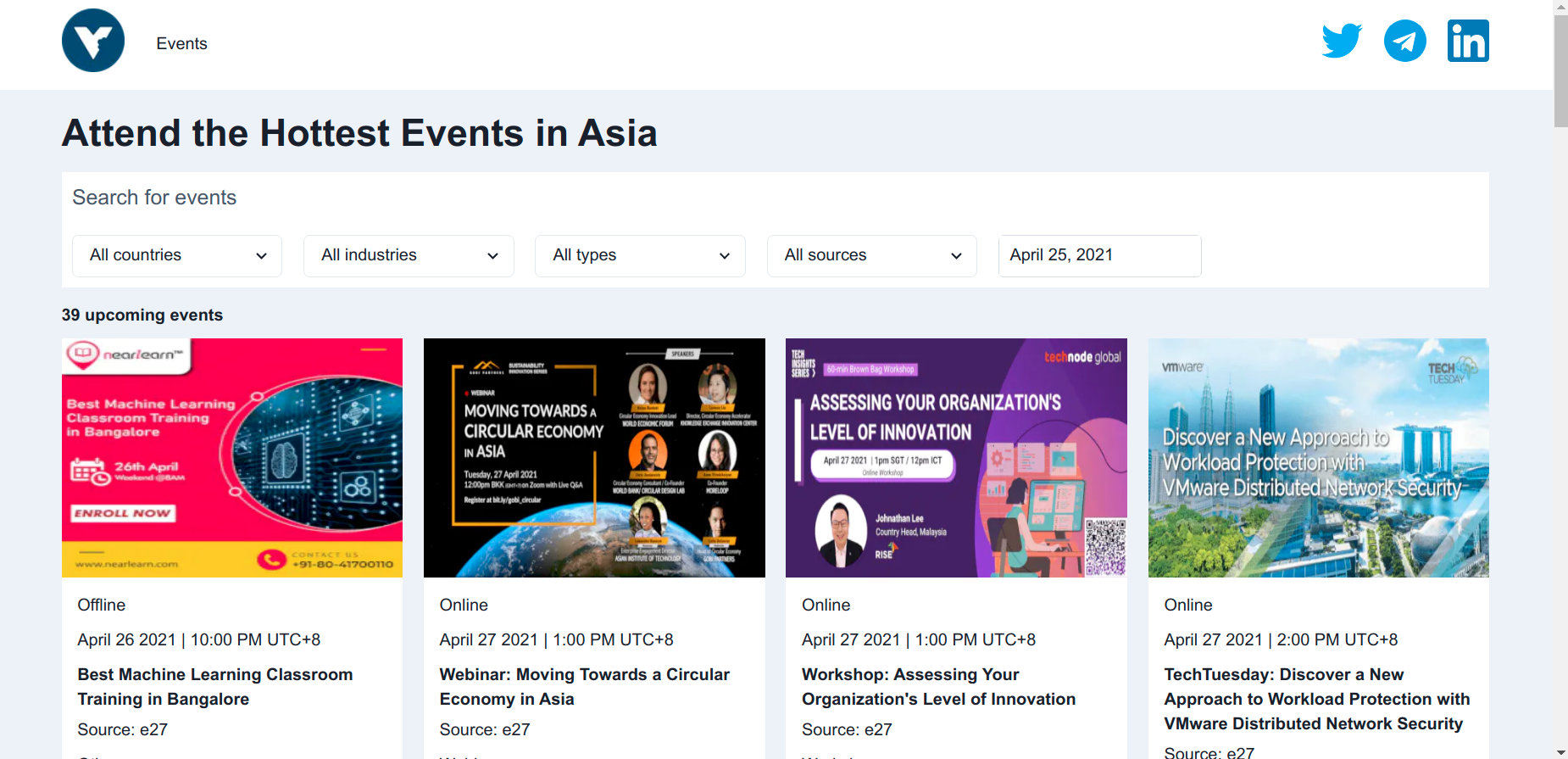
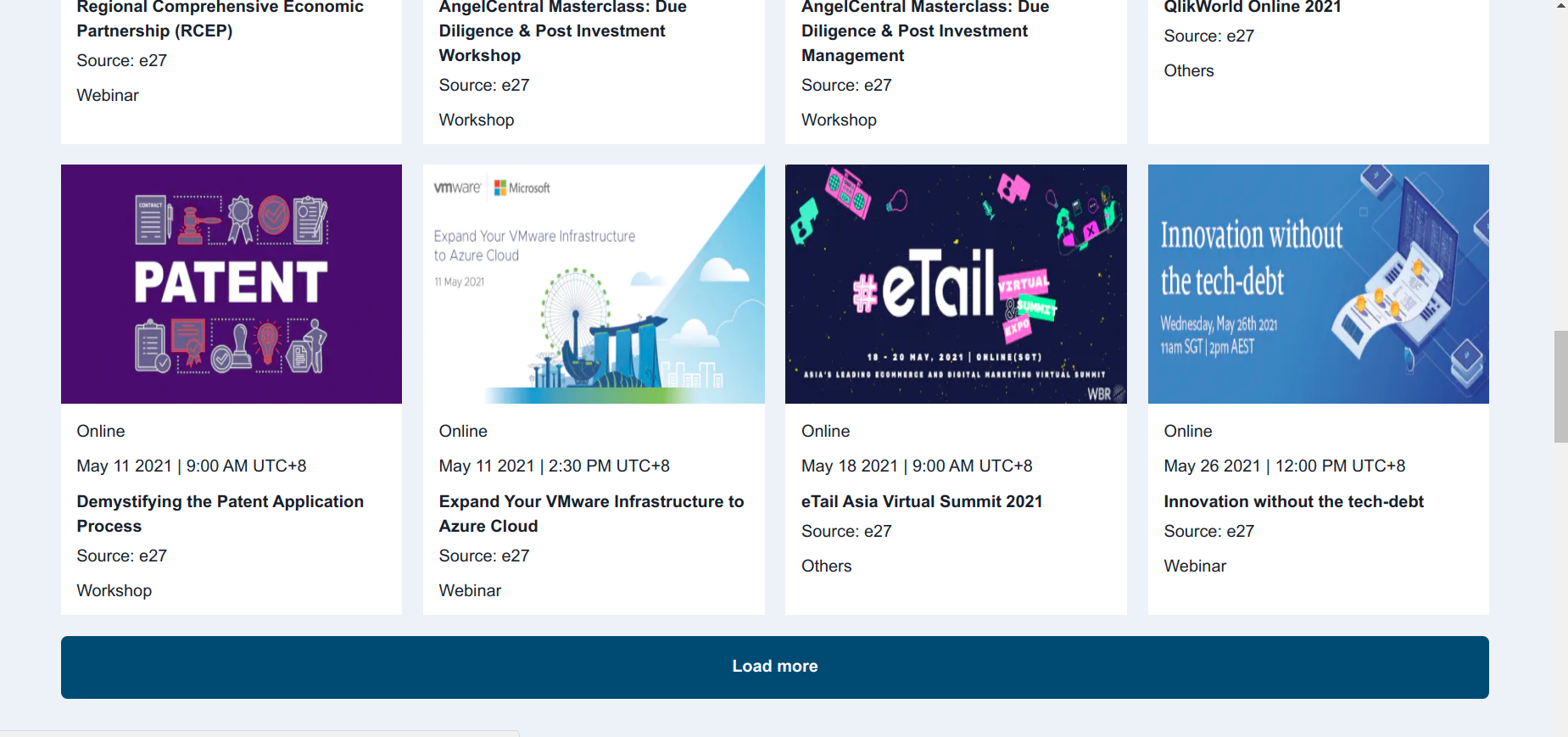
How venturebites started
I was approached by a friend who shared the idea of aggregating all things related to tech startups in a single portal, starting with an events directory. This will greatly alleviate the pains of having to visit multiple websites just to keep up to date on events related to tech startups in Asia.
Indeed, we live in a world where we are simply spoilt for choices that we "don't know what to choose", ending up in analysis paralysis.
Being a tech guy, I did not think too much of the business model but thought of it as an interesting opportunity to put some skills into practice while trying out new technology.
From the events side, we have Eventbrite, TechInAsia, e27, and many more.
System architecture
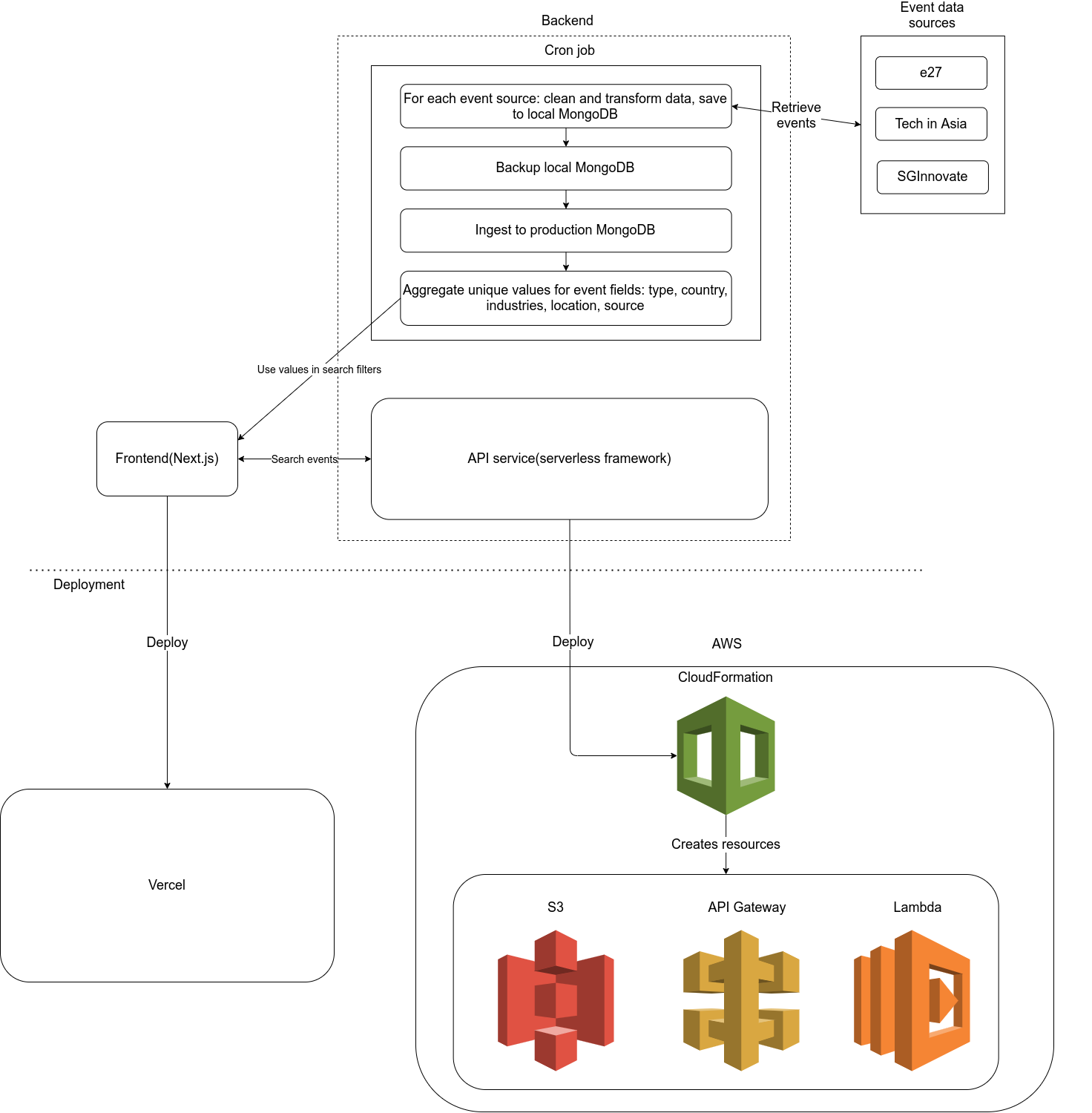
This is the architecture of Venturebites, which is quite simple.
On the backend, there is a background job that runs on a schedule on my machine, and an API service that serves queries. Both of them are built with typescript, on node.js.
This is deployed through serverless framework, which takes care of creating the necessary AWS resources.
On the frontend, there is a website/web app for people to view events, built with next.js(react). This is deployed through Vercel, because it is a sponsor of next.js, and therefore has a smooth native deployment workflow.
What's difficult 1: data extraction and unification
Even though this is a simple system, the process of gathering data from various sources and streamlining them into a unified format is tedious, and this will only get worse over time.
So far, I have integrated just 3 sources and am beginning to experience the mental overhead of managing the data.
But here's where a statically typed programming language really shines. By spending a little effort to define the data format of each source upfront, I have an idea of the data shape and can focus on consolidating them into a single destination format instead of having to do guesswork on all of them.
What's difficult 2: Time zone and offsets
E27
For e27, there is an API to retrieve events and another API to retrieve event detail. The challenge is in getting the right UTC offset, because the data isn't super clean.
Here's what an event looks like:
{
datestart: "2021-02-03 13:00:00",
dateend: "2021-02-05 09:00:00",
timezone: "(GMT+08:00) Kuala Lumpur, Singapore"
// some other fields
}
If I remember correctly, the timezone of the datetime is stored according to the event's location. Anyone viewing that event outside that timezone will see the wrong time.
Some processing needs to be done to extract the "+08:00" from timezone, and convert it into minutes.
If I want to work with the actual time zone string, more work has to be done because there are various forms that timezone can take.
Some examples are (GMT+05:30) Chennai, Kolkata, Mumbai, New Delhi, (GMT-08:00) Pacific Time (US & Canada).
After sorting out the event data, I used the event detail API to gather the remaining data such as location, targeted industries.
Thoughts on E27's API
In summary, E27's data isn't the nicest to work with because the data returned by their API is formatted according to how the frontend will display it, i.e. the backend and frontend are tightly coupled.
This is effective in terms of their implementation effort, but poor in terms of maintaining the system and opening up the API to third-party developers.
As a developer, what I would like to see is the datetime returned in ISO 8601 format, which the frontend can use to display it in the user's timezone.
Even better, the API can return the IANA timezone data directly, which is used to infer the UTC offset. This is important for countries that practise Daylight Saving Time(DST). Using an offset is acceptable in many cases, but fails when DST kicks in, or in the rare case when a country/city decides to changes its timezone.
Check out this youtube video and stackoverflow to learn about the difference between offset and timezone.
TechInAsia
TechInAsia's API is much easier to work with, regarding the management of timezone and offset.
Also, the data for the event and event detail are available in the same API, which may or may not be good from a technical perspective, but is certainly useful for the consumer.
Here's what an event looks like:
{
event\_start\_dt\_utc\_tz: "20210224T080000Z",
event\_end\_dt\_utc\_tz: "20210224T090000Z",
event\_duration\_date\_sgt: "Wednesday, 24 February 2021",
event\_duration\_time\_sgt: "4:00PM to 5:00PM (GMT+8)",
// some other fields
}
It returns both the local and UTC time. The UTC time can be easily formatted according to users' timezone.
Thoughts on TechInAsia's API
It is a pleasant experience using their API, because it is well designed.
SGInnovate
Retrieve events data from SGInnovate is the toughest of the 3 sources because there is no public API.
Instead, data has to be scraped from the html source. While webscraping is flexible - we can get almost any data we want, it is brittle. I used puppeteer, a headless chrome API, to scrape the data.
Here's what an event look like:
{
startDate: "Wednesday, January 13, 2021",
endDate: "Thursday, January 14, 2021",
// some other fields
}
After retrieving the event data which contains only the date, I visit the event detail page to extract the time and offset, which looks something like:
{
startTime: "11:00AM",
endTime: "12:00PM",
utcOffset: "+8"
}
Turns out that the way SGInnovate manage timezone and offset is similar to e27.
Thoughts on SGInnovate's scraping
This is the most tedious of all, because there is no real-time feedback from web scraping, unlike an API call that returns after 1 second.
It easily takes anywhere from 10 to 30 seconds just to get the first page of events. Then I need to inspect the HTML element to find the correct tags to extract the relevant data, console.log it out to check whether it worked.
Worst of all, I found that there are at least 4 variations of the HTML layout in the event detail page, which greatly disrupted my effort to extract the UTC offset.
I only managed to retrieve 14 out of 47 events data for 2021. After some more hours of tinkering, I gave up and moved on.
If anyone is adventurous and kind enough to help, please let me know.
Frontend
I am not a frontend guy, but have worked with react, redux, and a little on react native. I chose next.js because it is suitable for creating hybrid website/web app, which is related to static server-side generation and dynamic server-side rendering.
Static vs server-side generation
This topic of static generation vs server side generation has got me confused for a long time.
In short, server-side generation is what we think of as the old-school way of building websites. Each page request causes the server to dynamically render the page, and the browser performs a full refresh.
Static generation is still server-side generation, but it is done at build time, instead of run time. This is the method used for websites built on JAMstack.
With react, however, we can combine the best of both worlds, which is what next.js provides!
UI library
I tried Chakra UI, which is designed with composability, accessibility, and great developer experience in mind.
Out of all the UI libraries I have used(bootstrap, ant design, tailwind), I like Chakra the best.
Regarding CSS modules and CSS in JS(styled components), I originally liked the idea of styled components, being able to compose layered components, but never using it to the point of feeling productive.
After some time, I switched over to CSS module, and managing CSS became a simple task of isolating the styles for each file.
Data fetching
The data management layer is the meat of all frontend SPA.
I am fairly comfortable with redux and redux saga, but decided to try out swr, a hook for data fetching, which offers built-in cache, automatic refetching, and deduplication.
It is easy to use, but I did not find a clean way to manage the code.
Here's what the data fetching for infinite scrolling look like:
const {
size: ongoingEventPage,
setSize: setOngoingEventPage,
data: ongoingResult,
error: ongoingError,
isLoading: ongoingIsLoadingInitial,
} = useEventsInfinite(ongoingEventQuery());
const ongoingIsLoadingMore = isLoadingMore(
ongoingIsLoadingInitial,
ongoingEventPage,
ongoingResult
);
const lastFetchedOngoingEventResult = lastFetchedResult(ongoingResult);
const {
count: ongoingEventsCount,
data: lastFetchedOngoingEvents,
hasNextPage: hasMoreOngoingEvents,
} = lastFetchedOngoingEventResult;
const ongoingEvents: any\[\] = \[\];
ongoingResult?.forEach((result) => {
if (!justMounted) {
if (ongoingEvents.length === 0) {
sendGAEvent(GAEvents.EventSearch, {
eventSearch: {
...ongoingEventQuery(),
page: 1,
},
});
} else if (ongoingEvents.length > 0) {
sendGAEvent(GAEvents.EventSearchLoadMore, {
eventSearch: {
...ongoingEventQuery(),
page: ongoingEventPage,
},
});
}
}
justMounted = false;
ongoingEvents.push(...result?.payload?.data);
});
The functions referenced from above are defined as follow:
export const useEventsInfinite = (query: Record<string, any>) => {
const { data, error, size, setSize } = useSWRInfinite(
(page: number): string => {
query.page = page + 1;
const url = \`${BASE\_URL}/events/?${querystring.stringify(query)}\`;
return url;
},
fetcher
);
return { data, size, setSize, error, isLoading: !error && !data };
};
export const fetcher = (url: string) => fetch(url, { headers }).then((r) => r.json());
export const isLoadingMore = (
isLoading: boolean,
page: number,
result: any\[\] | undefined
): boolean => {
return (
isLoading || (page > 0 && result?.\[page - 1\]?.payload?.data === undefined)
);
};
export const lastFetchedResult = (result: any\[\] | undefined): any => {
return result?.\[result?.length - 1\]?.payload || {};
};
Not sure what you think, but this is a monstrosity of a quick hack that is put together just to "make things work". It is totally possible that I am using SWR wrongly, and there is a much cleaner way of doing things.
Besides CSS, data fetching is one of the major reasons why frontend development is so complicated, and there is no easy way out.
One could go the redux way, which offers a well-defined data workflow but have to write tons of boilerplate code and handle normalisation of data, and other out-of-the-box features that SWR or other built-in cache libraries offer.
Data integration is tough
Now, come to think of it, I have great admiration for the work that big data integrators like segment, zapier, have done. I cannot imagine how much effort it takes just to maintain the system's reliability and uptime.
This speaks to the fact that real-world data is always messy, some more than others.
But data is all around us. Those who can gather data of disparate forms, make sense of it, and provide value to others will stay ahead.